Classification de sons d'oiseaux, BirdCLEF+ 2026 (Kaggle)
Un pipeline de deep learning pour la reconnaissance multi-label d'espèces d'oiseaux à partir d'enregistrements sonores, …
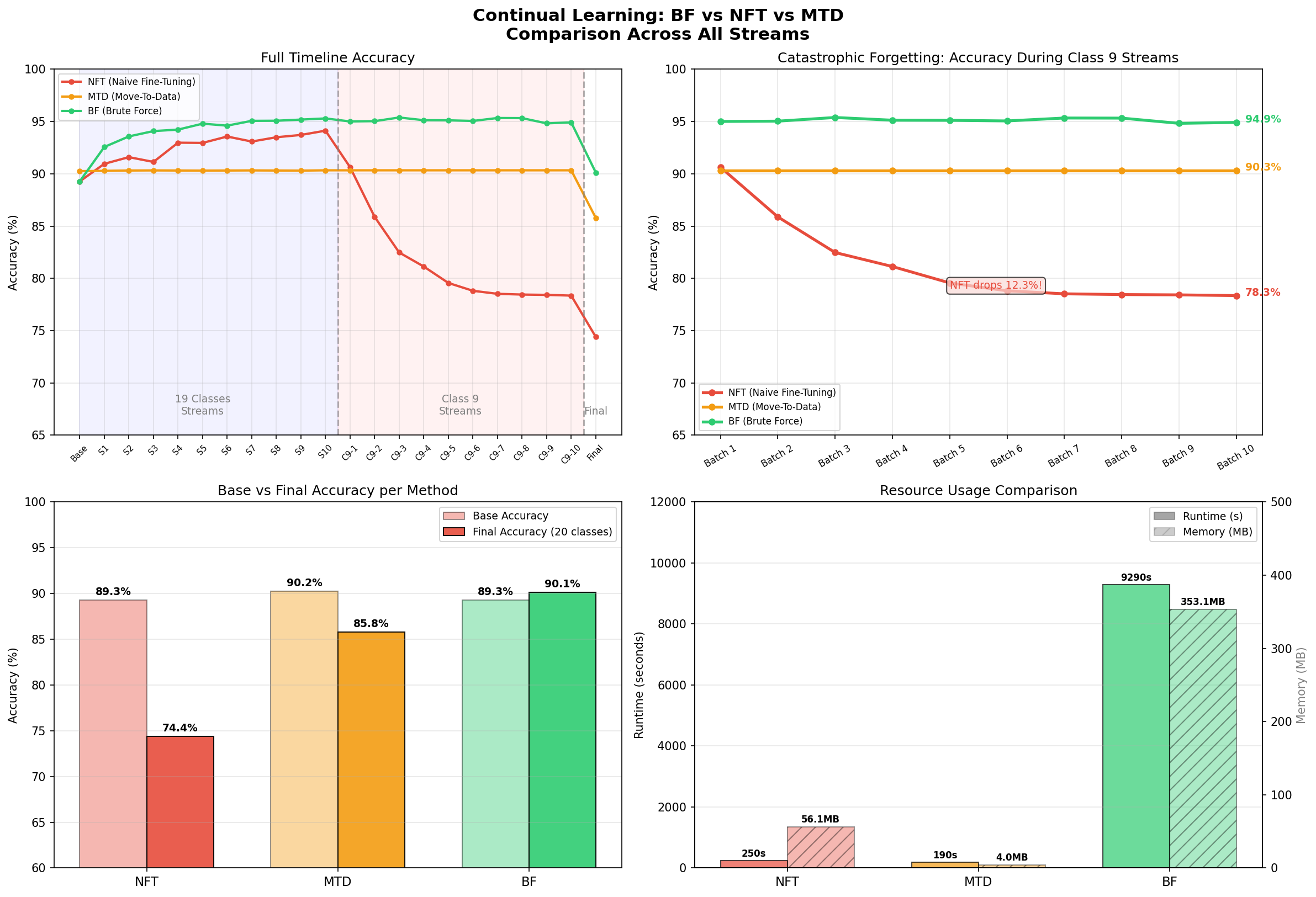
Ce projet simule un scénario d'apprentissage en ligne (Online/Incremental Learning) où un réseau de neurones convolutif (CNN) doit apprendre à partir de flux de données successifs, tout en faisant face à l'apparition d'une nouvelle classe inédite (le chiffre 9 de MNIST, volontairement mis de côté au départ).
Le CNN utilisé est identique pour les trois méthodes afin de garantir une comparaison équitable : deux blocs de convolution (1→32→64→128 filtres) suivis de deux couches fully-connected (fc1: 256 neurones, fc2: 20 sorties). L'optimiseur Adam a été réimplémenté manuellement (MyAdam) avec correction de biais, gestion du weight decay L2 et ajustement dynamique du taux d'apprentissage.
Trois stratégies sont comparées sur 5000 échantillons initiaux (19 classes), puis 10 flux de données pour les 19 classes, et enfin 10 flux introduisant la classe 9 :
Brute Force (BF) : réentraînement complet sur toutes les données à chaque flux. Précision finale : 90.12%, mais coût prohibitif (9290s, 353 Mo).
Naive Fine-Tuning (NFT) : entraînement uniquement sur les nouvelles données. Rapide (250s, 56 Mo), mais souffre d'un oubli catastrophique sévère lors de l'ajout de la classe 9 : chute de 94.1% à 74.4%.
Move-To-Data (MTD) : le feature extractor est gelé après l'entraînement initial ; seule la couche fc2 est mise à jour via une règle géométrique sans rétropropagation. Précision finale : 85.78%, avec une stabilité remarquable tout au long des flux et une empreinte mémoire minimale (190s, 4 Mo).
En contexte de ressources limitées ou de volumes de données importants, MTD s'impose comme la solution la plus rentable et efficace. Dans le cas contraire, Brute Force reste la meilleure option pour une précision maximale. Pour une description complète du projet, consultez le fichier README sur GitHub.
Un pipeline de deep learning pour la reconnaissance multi-label d'espèces d'oiseaux à partir d'enregistrements sonores, …
Reproduction, extension et amélioration d'un modèle hypergraphique publié dans Nature Communications pour mesurer l'innovation dans …
Simulation et prédiction des communications dans un réseau P2P distribué avec déconnexions de nœuds, en …